Hive的执行过程
前言
- 基于HDP的解决方案搭建,版本
2.6.3.0-235
Hive版本: 1.2.1000
HDFS版本: 2.7.3
YARN版本: 2.7.3
Tez版本: 0.7.0
Hive的结构
- 没有在官网找到详细的架构图,放以下2个图,互相参考着看
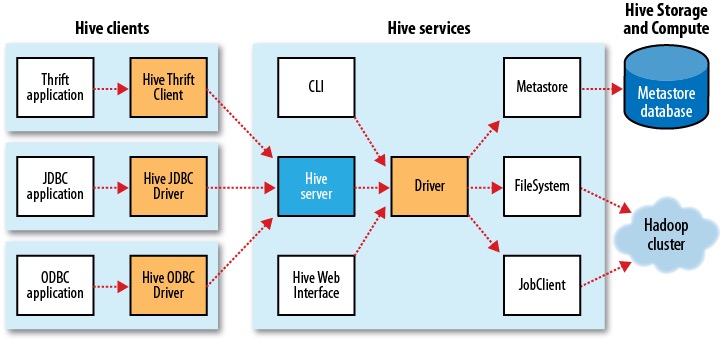
图片来自: Tom White. Hadoop: The Definitive Guide
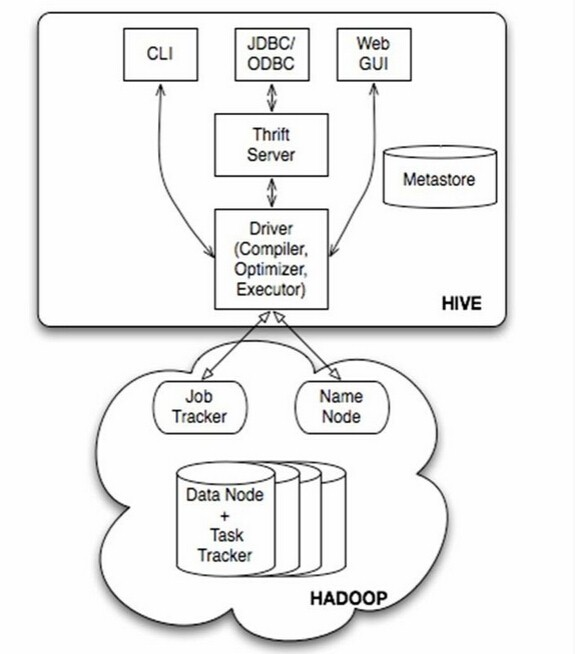
Hive主要包含服务端、客户端
1.客户端
- CLI
CLI(Command Line Interface): 通过命令行访问
- Thrift Client
支持Thrift方式连接Hive服务
- HiveWebInterface
通过浏览器访问Hive
2.服务端
- Hive Server: Thrift服务
thrift是facebook开发的一个软件框架,用来进行可扩展且跨语言的服务的开发,hive集成了该服务,能让不同的编程语言调用hive的接口。
- Driver
包括Complier、Optimizer和Executor,作用是将HQL解析、编译优化、生产执行计划,调用底层的计算引擎(mr, tez)。
- Metastore
存储数据的元信息。就是表的名字、表的列、表的分区、表的属性、表的数据所在目录。
Hive的执行过程以及涉及到的参数
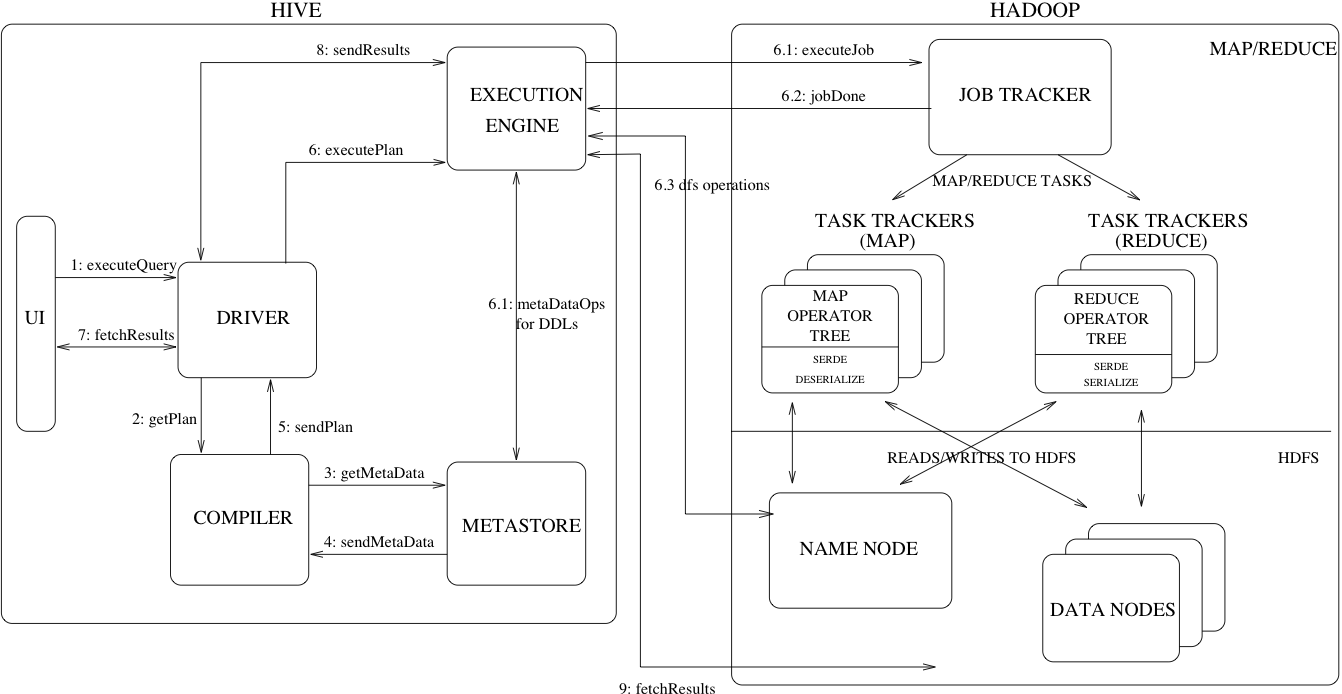
图片来自: https://cwiki.apache.org/confluence/display/Hive/Design#Design-HiveArchitecture
HQL经过Driver转换成MR或TEZ任务的过程如下
- Parser: 使用Antlr(定义SQL的语法规则,完成SQL词法,语法解析)将HQL转化成抽象语法树AST(Abstract Syntax Tree)
- Semantic Analyzer: 遍历AST,转换成查询块
- Logic Plan Generator: 将查询块转换成逻辑查询计划
- Logic Optimizer: 优化逻辑查询计划,合并不必要的ReduceSinkOperator,减少shuffle数据量
- Physical Plan Gernerator: 将逻辑查询计划翻译为物理计划(MR或TEZ任务)
- Physical Optimizer: 物理计划的优化,生成最终的执行计划
执行计划提交给Hadoop集群后,主要有三个执行阶段,Map阶段、Shuffle阶段、Reduce阶段,可以看一张图片直观的感受一下。

图片来自: Tom White. Hadoop: The Definitive Guide
Map阶段
- 以JOIN ON后面的字段作为Key、以Group By的字段作为Key、以Distinct的字段作为Key等
- 对Key进行排序
涉及参数
1 | dfs.block.size 文件块大小 |
Map数量
- 简单说Map数量根据文件数来的
1 | Math.max(minSize, Math.min(goalSize, blockSize)); |
1.确定splitSize大小
2.将目标文件按照splitSize进行分片,每一个分片会分配一个maptask进行处理
- 代码
Hadoop HDP-2.6.3.0-235-tag FileInputFormat.java
Shuffle阶段
- 根据Key的值进行Hash,并将Key/Value按照Hash(Key)推到不同的Reduce中
Reduce阶段
- 根据Key值进行Join操作,计算最终输出
涉及参数
1 | mapred.reduce.tasks 指定reduce的任务数量 |
Reduce数量
- 简单说Reduce数量是根据数据量来的
1 | Max(1, Min(hive.exec.reducers.max, ReducerStage estimate/hive.exec.reducers.bytes.per.reducer)) * hive.tez.max.partition.factor |